解释一下为什么数据文件最好采用单字符作为分隔符
本文出处:http://blog.csdn.net/chaijunkun/article/details/17279565,转载请注明。由于本人不定期会整理相关博文,会对相应内容作出完善。因此强烈建议在原始出处查看此文。
距离上次写技术博客已经有半年时间了,年尾我觉得有必要写点东西总结一下经验,分享给大家。近期在做一个数据同步的项目,从数据中心拿到定时分发的导出文件后,按照固定字段的含义再逐行解析,然后进一步分析后倒入到我这边的数据库。需求简单就是这样,我们来看个例子:
2013-09-29^_^21635265^_^测试标题^_^10^_^20^_^15
假设上面的例子是文本数据的其中一行。在这个例子中,列分隔符采用的是^_^(注意,是多字符的),字段定义分别是发布日期^_^文章ID^_^文章标题^_^评论数^_^点击数^_^顶数考虑到对数据中心的信任,我们忽略了“发布日期”、“文章ID”、“评论数”、“点击数”和“顶数”这些字段的非法情况,而将重点放在了分析标题上,因为标题是用户指定的,而可以输入任何可见字符,因此我们还考虑到了在文章中包含我们的分隔符的情况,所以在data.splite()之后采用了掐头去尾的算法,前两个字段正常分析,然后倒着来,从“顶数“,”点击数”和“评论数”分析,剩下的就是标题了。可是我们只考虑了标题中如下形式:
测试标题^_^、测试^_^标题、^_^测试标题
而没有考虑到这样的情况:测试标题^_
也就是说标题中的末尾带有一半分隔符,这样从逻辑上和真正分隔符的前一半正好能拼成一个合理的分隔符,如:2013-09-29^_^21635265^_^测试标题^_^_^10^_^20^_^15
所以在拆分字段的时候评论数字段就被拆成了“_^10”,这种情况下是没有办法将其转换为Integer类型的,故而报错。说起来在这个项目中采用什么样的分隔符还是很早前其他同事定的,直到发生这个问题才觉得有必要改成单个字符,这样就不会产生歧义了。
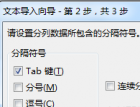
后来在我用Excel导入其它数据进行分析的时候发现它早就注意到这个问题了,在指定自定义分隔符的时候只允许采用单字符:


>更多相关文章
- 11-06Hadoop是目前大数据领域最主流的一套技术体系
- 11-06大数据和人工智能:三个真实世界的用例
- 11-06为什么说,大数据与行业专家是“共生”关系?
- 11-06Python数据可视化:箱线图多种库画法
- 11-06这种思路讲解HDFS你肯定没见过?快速入门Hadoop必备
- 11-06媲美Pandas的数据分析工具包Datatable
首页推荐

佛山市东联科技有限公司一直秉承“一切以用户价值为依归
- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 11-28Bossjob宣布上线AI翻译功能
- 11-28腾讯应用宝电脑版推小宝AI助手 部分功能已
- 11-28周鸿祎亲自上阵演短剧,将于发布会上播出
- 11-28机构:2024第三季度全球NAND闪存产业营收增
- 11-18LG新能源宣布与Bear Robotics达成合作,成为
相关文章








24小时热门资讯
24小时回复排行
热门推荐

最新资讯




操作系统
黑客防御




 粤公网安备 44060402001498号
粤公网安备 44060402001498号