10分钟带你打开深度学习大门,代码已开源

本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
深度学习技术的不断普及,越来越多的语言可以用来进行深度学习项目的开发,即使是JavaScript这样曾经只是在浏览器中运行的用于处理轻型任务的脚本语言。
TensorFlow.js是谷歌推出的基于JavaScript的深度学习框架,它提供的高级API使得开发可以直接在浏览器中运行的深度学习算法变得轻而易举。
这不,美国的一位老哥Gant Laborde使用TensorFlow.js开发了一款是用深度学习技术在浏览器中识别“石头剪刀布”游戏手势的网页应用,放出了demo并将代码开源在了Github上。
对于JavaScript开发者来说,这是打开深度学习大门的极佳入门教材。只需10分钟,你就可以训练一个准确率可观的手势识别模型,并且调用摄像头对实时视频中的手势进行识别。

△使用运行在浏览器中的深度学习模型识别手势
在一切开始之前
在打开新世界的大门之前,我们总是需要做一些准备工作。
在这里,给大家简单地介绍一下典型的深度学习算法的开发步骤,目的是希望读者们在接下来的操作中明确地知道自己在做什么,而不仅仅是点几个按钮罢了。
这里不会涉及任何艰涩的数学公式,请放心食用。
我们平常所说的深度学习算法,更确切地说,应该是基于深度神经网络的算法(或者说模型)。
这里并不需要知道深度神经网络究竟是个什么东西(你可能需要再花百倍于此的时间才有可能搞明白其具体原理),只需要知道,它可以视作是一个函数f,一个很难用简单公式表达出来的函数。
所谓函数,就要有自变量x和因变量y。
自变量x,我们一般称之为输入(input),在这个问题中就是一张做出“石头”、“剪刀”或“布”手势的手的图像。
而因变量y,我们一般称之为输出(output),在这个问题中是三个取值为0-1的数值,分别对应输入手势是“石头”、“剪刀”和“布”的概率。
我们依靠这个函数f得到我们想要的结果,但是f并不是天上掉下来的,它由人为选取的模型和(大量的)模型参数组成。
其中模型参数往往由大量数据学习得到,这个让模型学习参数的过程我们称之为模型训练(train),是深度学习算法开发中最关键的一步。
在这个问题中,我们需要大量(x,y)数据对来进行训练,也就是大量(图像,手势)数据对,如(图像1,剪刀)、(图像2、石头)、(图像3、布)…… 这些数据对往往需要由人为搜集、标注得到。
我们可以通过一些评估指标来衡量模型的好坏程度,比如在这个问题中,手势识别的准确度。通过这些评估指标我们可以验证(validate)模型是否经过了充分的训练、效果有没有达到我们的预期。如果是,我们可以将其部署投入使用,测试其在现实情况中的表现。
总结来说,一个深度学习算法的开发,需要经过数据准备、模型选择与训练、模型效果评估、模型测试这四个阶段。
现在,正式开始!
数据准备
我们之前提到,需要大量的(图像,手势)数据对来进行模型的训练。搜集这样的数据无疑是一个繁琐的工作,拍照、标注……
幸运的是,谷歌工程师Laurence Moroney为我们提供了这样一个数据集,其中包含了白色背景下的三种手势共2892张图像及对应的手势标签,一些例子:

△Moroney提供的数据集的一些例子
数据集网址:
http://www.laurencemoroney.com/rock-paper-scissors-dataset/
一切看似都是这么的顺利。等等,我们怎么把这么一坨图像搞进浏览器里去?
在浏览器里执行JavaScript,好像并不能从本地读取文件。
一个显见的想法是,我们把训练数据当做网页中的图片,读进DOM的img元素中。我们先将训练数据中每一张图像“拉直“成1像素高的图像,再将所有图像一行一行堆叠在一起。
比如我们原图大小为64x64,“拉直”之后尺寸为1x4096,训练集的2520张图像堆叠后形成大小为4096x2520的巨大图像(虽然它在视觉上已经失去了意义),像下面这样。
这张巨大图像被称为精灵表单(sprite-sheet),包含了许多小图像。
这个网页应用的作者提供了生成sprite-sheet的Python代码,在github仓库根目录的spritemaker文件夹下。

△生成的尺寸为4096x2520的sprite-sheet
在demo页面中,点击“Load and Show Examples(读取数据并展示样例)”按钮,等待一阵,我们可以看到数据被读入了浏览器,并且出现了一个侧边栏,其中展示了42张从数据集中随机选取的图像。
这个侧边栏由TensorFlow Visor提供,可以帮助我们直观地观察模型的训练过程,我们可以随时按下键盘左上方的`键切出或隐藏该面板。

△TensorFlow Visor界面中展示的数据样例
模型选择、训练与效果评估
接下来我们将面临抉择。
两个按钮摆在我们的面前,“Create Simple Model(创建简单模型)”和“Create Advance Model(创建高级模型)”。

先从简单的来吧,我们点击“Create Simple Model”。按`键切出TensorFlow Visor面板,可以看到上面出现了刚刚创建的简单模型的网络结构,这是一个5层的卷积神经网络模型(Flatten层不计入层数),你只需要知道它可以看做是一个一个相对简单函数的堆叠,并且这确实是一个非常简单基础的卷积神经网络模型。

△TensorFlow Visor界面中展示的网络结构
点击“Check Untrained Model Results(查看未训练模型结果)”,面板中出现了一个Accuracy(准确率)表格,和一个矩阵,它们就是这个问题中我们对于模型的评价指标。
准确率表格中,每一行是一个手势类别的准确率值;矩阵中,手势X的行和手势Y的列确定的单元格代表实际是手势X,被算法认为是手势Y的图像数量,这样的矩阵我们叫做“混淆矩阵”,因为它展现了算法对于两两手势容易搞混的程度。
可以看到,因为我们的模型还没有进行训练,所以算法认为所有输入图像中的手势都是“剪刀”,它还很懵懂。
那么就开始训练它吧!点击“Train Your Simple Model(训练简单模型)”!TensorFlow Visor面板中出现了“Model Training(模型训练)”一栏,展示了训练中实时的准确率(Accuracy)和损失(Loss)值,正常情况下,我们应该可以看到随着训练的进行,准确率不断上升,而损失不断下降。训练在12个epoch(60个batch)后停止。

△TensorFlow Visor界面中展示的训练进程
训练结束后,点击“Check Model After Training(查看训练后模型结果)”。在原来的准确率表格和混淆矩阵下方出现了训练后模型的准确率(Trained Accuracy)和混淆矩阵(Trained Confusion Matrix)。
Amazing!训练后,模型在验证数据上对于三种手势的识别准确率都超过了95%,混淆矩阵也是健康的(对角线深,其余浅)。
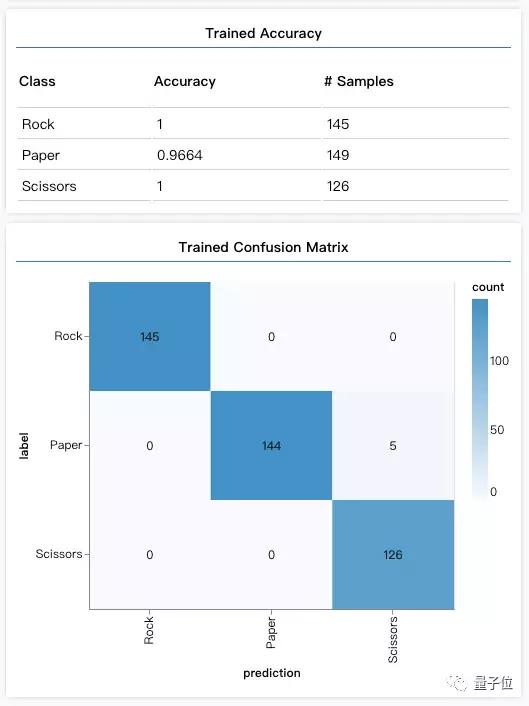
△TensorFlow Visor界面中展示的训练后模型效果
你也许会想,“高级的东西总比简单的东西好吧?高级模型效果一定更好。” 其实这是一个常见的误区。
如果你选择“Create Advance Model(创建高级模型)”,重复上述操作,会发现高级模型不仅训练时间更长,效果也不如简单模型那么好。
更进一步,高级模型如果训练时间过长,会出现过拟合(overfitting)的情况。
过拟合是指,模型太注重完美拟合训练数据,导致其虽然在训练数据上的表现极佳,但是对于训练数据之外它没有见过的数据效果较差,或者我们也会说模型此时的泛化(generalize)能力较差。
模型测试
既然已经有了一个表现很不错的简单模型,那么让我们立刻将它投入使用吧!
点击“Launch Webcam(打开摄像头)”,对准一面白墙,对着摄像头做出不同的手势,应用会定时捕捉视频图像,通过训练好的模型算法,告诉你当前手势属于三种类别的概率,是不是很酷炫呢?
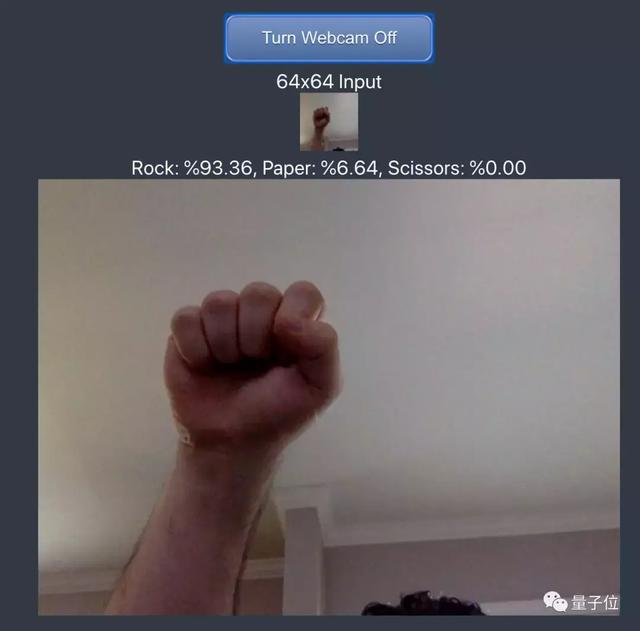
△使用已训练模型识别视频中的手势
Done!
至此,你已经在完全在浏览器中训练了一个用于手势分类的深度学习模型,通过一些指标验证了它的有效性,并且在现实情境中对它进行了测试。
尽管这些步骤很简单,但你了解它们在做什么——欢迎来到深度学习的世界!
传送门
源代码仓库:
https://github.com/GantMan/rps_tfjs_demo
Demo页面:
https://rps-tfjs.netlify.com/
更多信息来自:东方联盟网 vm888.com
- 02-23人工智能和python之间有什么联系?为何用python?
- 03-022021年值得关注的人工智能趋势
- 03-02人工智能和物联网——5个新兴的应用案例
- 03-02人工智能将使纺织工业的生产过程实现数字化和自动化
- 03-02如何应对人工智能在医疗保健领域的挑战
- 07-21人工智能、物联网和大数据如何拯救蜜蜂


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 12-05亚马逊推出新一代基础模型 任意模态生成大模
- 12-05OpenAI拓展欧洲业务 将在苏黎世设立办公室
- 12-05微软质疑美国联邦贸易委员会泄露信息 督促其
- 12-05联交所取消宝宝树上市地位 宝宝树:不会对公
- 12-04企业微信致歉:文档打开异常已完成修复
















 粤公网安备 44060402001498号
粤公网安备 44060402001498号