C++网络安全工具编程 Web目录扫描器
建立socket连接的过程请参考《C++网络安全工具编程(一)connect端口扫描器》中的基础部分。
当成功与目标服务器的80端口(即http服务端口)建立连接后,我们即可通过发送请求和接收消息来与目标网站服务器进行信息交互,大部分浏览器的实现也是基于此原理。
那么,应该怎样与目标网页服务器进行交互呢。这里我们需要先了解一下Http报文。
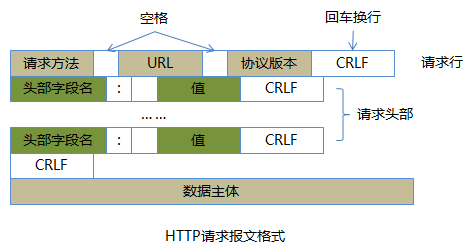
先来看下Http请求报文

(图来自网络)
首先如图
Http报文包括了:请求行、请求头部、空行、请求数据
(1)请求行
请求行由请求方法字段、URL字段和HTTP协议版本字段组成,用空格分隔。如,GET /index.html HTTP/1.1
HTTP协议的请求方法最常用的GET方法和POST方法。
GET方法:
GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,GET方法为显性传参,通常用于传递非安全需要的信息。
例如:/index.php?id=1
GET方法最多只能像服务器发送1024byte的数据,同时GET报文没有报文体的,只有头部,数据在GET url?xxx=xx中传出
POST:
当客户端给服务器提供信息较多时可以使用POST方法。此方法为隐性传参,通常用于帐号密码的传递。
POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,可用来传送文件。
(2)请求头部
请求头部由Key/Value对组成。请求头部用于通知服务器有关于客户端请求的信息:
User-Agent:客户端浏览器类型。
Accept:客户端内容类型列表。
Host:目标主机IP。
(3)空行
空行用于发送回车符和换行符,通知服务器请求头完毕。
若不发送空行,服务器会认为本次请求的数据尚未完全发送,会处于等待状态。
(4)请求数据
这是在POST方法中独有的。POST常用于表单提交,通常方法有Content-Type和Content-Length。
我们来分别看一下POST方法以及GET方法的Http请求报文
POST报文头:
POST index.php HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: www.beitown.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:close //连接方式
//空行 /r/n/r/n
name = beitown//发送的数据 (加在空行之后)
GET报文头:
GET index.php?name=beitown HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: www.beitown.com
Connection:Keep-Alive //连接方式
以下代码将使用GET方法发送一个Http头请求,并获取网页服务器返回的信息
#include "stdafx.h"#include <iostream>#include <Winsock2.h>using namespace std;#pragma comment(lib,"ws2_32.lib")int _tmain(int argc, _TCHAR* argv[]){ //初始化Windows Sockets 动态库 WSADATA wsaData; if(WSAStartup(MAKEWORD(2,2),&wsaData)!=0) { cout<<"找不到可使用的WinSock dll!"<<endl; return 1; } //创建套接字 SOCKET sClient=socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); if(sClient==INVALID_SOCKET) { cout<<"创建客户端socket失败!"<<endl; return 1; } //连接服务器 SOCKADDR_IN addrServ; addrServ.sin_family=AF_INET; addrServ.sin_addr.S_un.S_addr=inet_addr("74.53.53.200"); addrServ.sin_port=htons(80); if(connect(sClient,(sockaddr *)&addrServ,sizeof(sockaddr))==SOCKET_ERROR) { cout<<"连接服务器失败!"<<endl; closesocket(sClient); return 1; } else cout<<"连接服务器成功!"<<endl; char * content = "index.php"; string str=""; str.append("GET /"); str.append(content); str.append(" HTTP/1.1"); str.append("/r/nHost:"); str.append("www.beitown.com"); str.append("/r/nAccept:*/*"); str.append("/r/nConnection:Keep-Alive"); str.append("/r/n/r/n"); //发送数据 int retval=send(sClient,str.data(),str.length()+1,0); if(retval==SOCKET_ERROR) { cout<<"发送数据失败!"<<endl; } //接收数据 char buf[1024]; memset(buf,0,1024); retval=recv(sClient,buf,1024,0); if(retval==SOCKET_ERROR) { cout<<"接收数据失败!"<<endl; } cout<<buf<<endl; getchar(); //关闭套接字,释放资源 closesocket(sClient); WSACleanup(); return 0;}通过对目标网页服务器80端口建立的socket连接,发送GET请求,服务器获取GET请求后返回HTTP响应头,若网页可以访问则在相应头后还会发送网页HTML编码
如图

服务器返回的Http响应头格式如下图
(本图来自网络)
Http响应头大致分为如下几种
1xx:信息响应类,表示接收到请求并且继续处理
2xx:处理成功响应类,表示动作被成功接收、理解和接受
3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理
4xx:客户端错误,客户请求包含语法错误或者是不能正确执行
5xx:服务端错误,服务器不能正确执行一个正确的请求
Demo中收到200 OK表示网页可以被成功访问。
以上即完成了一个最简的C++访问目标WEB页的过程。
接下来我们将此Demo进一步拓展,制作一个自己的网页目录扫描器,又称网站挖掘机、目录爆破器。
对网站目录的扫描其原理就是以穷举猜测常用目录名的方式进行爆破,这里就需要使用到一个字典,通常用txt格式即可。程序读入字典里实现写好的常用目录路径,并依次进行试探性扫描。读入txt文件的代码如下:
fstream file; file.open("dir.txt",ios::in); if(!file) cout<<"file not founded"<<endl; string str; while( getline(file,str) ) { cout << "Read from file: " << str << endl; } file.close();当程序目录下有dir.txt文件时,程序将逐行读取txt文件中的数据并存入字符串str中。
整合代码,最终程序如下
#include "stdafx.h"#include <iostream>#include <Winsock2.h>#include <fstream>#include <string>using namespace std;#pragma comment(lib,"ws2_32.lib")int _tmain(int argc, _TCHAR* argv[]){ //初始化Windows Sockets 动态库 WSADATA wsaData; if(WSAStartup(MAKEWORD(2,2),&wsaData)!=0) { cout<<"找不到可使用的WinSock dll!"<<endl; return 1; } SOCKADDR_IN addrServ; addrServ.sin_family=AF_INET; addrServ.sin_addr.S_un.S_addr=inet_addr("74.53.53.200"); addrServ.sin_port=htons(80); SOCKET sClient; //打开字典文件 fstream file; file.open("dir.txt",ios::in); if(!file) cout<<"file not founded"<<endl; string dir; while( getline(file,dir) )//逐行读取字典 { //创建套接字 sClient=socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); if(sClient==INVALID_SOCKET) { cout<<"创建客户端socket失败!"<<endl; return 1; } //连接服务器 if(connect(sClient,(sockaddr *)&addrServ,sizeof(sockaddr))==SOCKET_ERROR) { cout<<"连接服务器失败!"<<endl; closesocket(sClient); return 1; } //else //cout<<"连接服务器成功!"<<endl; char * content = "index.php"; //请求的资源 string str=""; str.append("GET /"); str.append(dir); str.append(" HTTP/1.1"); str.append("/r/nHost:"); str.append("www.beitown.com"); str.append("/r/nAccept:*/*"); str.append("/r/nConnection:Keep-Alive"); str.append("/r/n/r/n"); //发送数据 int retval=send(sClient,str.data(),str.length()+1,0); if(retval==SOCKET_ERROR) { cout<<"发送数据失败!"<<endl; } //接收数据 char buf[16];//只接受前16个字符即可 memset(buf,0,16); retval=recv(sClient,buf,16,0); buf[15] = '/0';//字符串结尾 if(retval==SOCKET_ERROR) { cout<<"接收数据失败!"<<endl; } cout << "/" << dir <<": >> " << buf << endl; closesocket(sClient); } file.close(); getchar(); getchar(); //关闭套接字,释放资源 WSACleanup(); return 0;}1.Http协议通常是没有长连接这一概念的,所以在目标服务器80端口建立socket连接后,
当客户端发送一次http请求,服务器响应请求之后,会主动关闭这个客户端的socket连接。
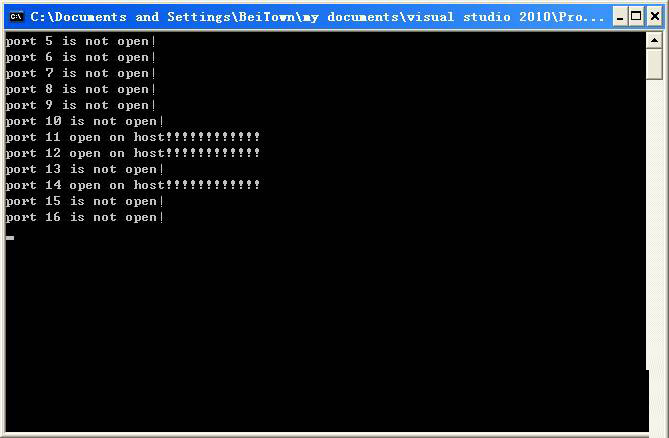
关于字典基于安全考虑这里就不提供给大家了,上一张运行截图

扫描器依次对目标网站进行了目录及文件的猜测,如图,目标网站存在index.php这个文件并且可以正常访问,返回 200 OK 代码。
以上即为一个最简的Web目录扫描器的制作过程及全部源码,更多的功能大家请自行添加,本文意在概述最简功能的实现,以此抛砖引玉,举一反三。
Hack亦有道,请勿将本篇中所阐述的内容用于非法用途。
本篇到此,谢谢关注。
BeiTown
2013.04.30
- 09-26多线程开发中线程数量设计问题
- 09-26Go语言和Java、Python等其他语言的对比分析
- 09-26Java语言为什么经久不衰?且总能霸占编程语言排行榜首?
- 09-26浅谈10个提升应用程序10倍性能的技巧
- 06-10利用Python语言判断狗狗年龄的程序
- 12-09用c写了个后台扫描

- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-21中国产品数字护照体系加速建设
- 04-21上海口岸汽车出口突破50万辆
- 04-21外媒:微软囤货GPU以发展AI
- 04-21苹果手表MicroLED项目停滞持续波及供应链
- 04-21三部门:到2024年末IPv6活跃用户数达到8亿











 粤公网安备 44060402001498号
粤公网安备 44060402001498号