图解HBase--大数据平台技术栈
HBase简介
HBase是一个分布式的、面向列的开源数据库存储系统,是对Google论文BigTable的实现,具有高可靠性、高性能和可伸缩性,它可以处理分布在数千台通用服务器上的PB级的海量数据。BigTable的底层是通过GFS(Google文件系统)来存储数据,而HBase对应的则是通过HDFS(Hadoop分布式文件系统)来存储数据的。
HBase不同于一般的关系型数据库,它是一个适合于非结构化数据存储的数据库。HBase不限制存储的数据的种类,允许动态的、灵活的数据模型。HBase可以在一个服务器集群上运行,并且能够根据业务进行横向扩展。
HBase特点
海量存储:HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与HBase的记忆扩展性息息相关。正是因为HBase的良好扩展性,才为海量数据的存储提供了便利。
列式存储:列式存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定,而不用指定列。
极易扩展:HBase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储能力(HDFS)的扩展。
高并发:目前大部分使用HBase的架构,都是采用廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,HBase的单个IO延迟下降并不多。
稀疏:稀疏主要是针对HBase列的灵活性,在列族中,可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间。
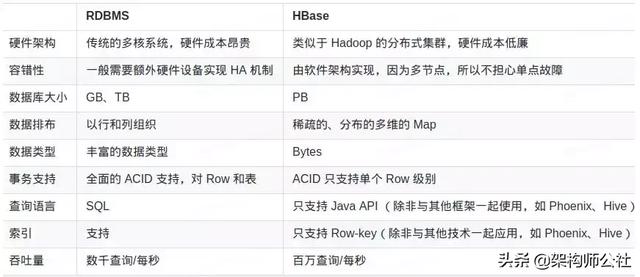
HBase与关系型数据库对比
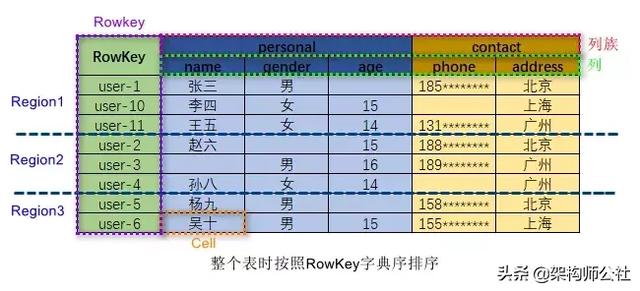
HBase数据模型
- Namespace(表命名空间):表命名空间不是强制的,如果想把多个表分到一个组去统一管理的时候才会用到表命名空间。
- Table(表):一个表由一个或者多个列族组成。
- Row(行):一个行包含了多个列,这些列通过列族来分类。行中的数据所属列族只能从该表所定义的列族中选取,不能定义这个表中不存在的列族。
- Column Family(列族):列族是多个列的集合。
- Column Qualifier(列):多个列组成一个行。列族和列用:Column Family:Column Qualifier表示。列是可以随意定义的,一个行中的列不限名字,不限数量,只限定列族。
- Cell(单元格):一个列中可以存储多个版本的数据,每个版本就称为一个Cell。也就是说在HBase中一个列可以保存多个版本的数据。
- Timestamp(时间戳/版本号):用来标定同一个列中多个Cell的版本号。当在插入数据的时候,如果不指定版本号,系统会自动采用系统的当前时间戳来作为版本号,也可以手动指定一个数字作为版本号。
- Rowkey(行键):用来标识表中唯一的一行数据,以字节数组形式存储,类似关系型数据库中表的主键。rowkey在HBase中时严格按照字典序排序的。
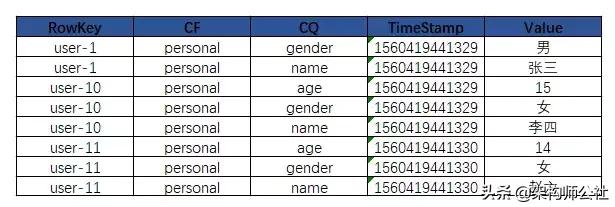
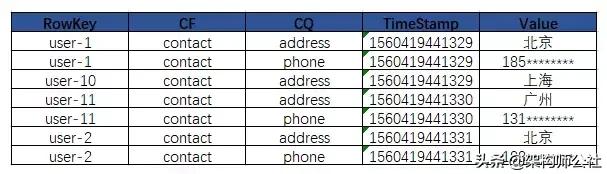
物理视图
在物理存储上,数据是以Key-Vaule对形式存储,每个Key-Value只存储一个Cell里面的数据,不同的列族存储在不同的文件中,每个逻辑单元格(Cell)会对应一行数据,有Timestamp标记版本,每次插入、删除都会生成一行数据(append-only,写效率高)。
HBase体系架构
HBase的服务器体系结构遵循简单的主从服务器架构,一般一个HBase集群由一个Master服务(高可用的话,至少两个)和1个或多个RegionServer服务组成。Master服务负责维护表结构信息,实际的数据是保存在RegionServer上,最终RegionServer保存的表数据会直接存储在HDFS上。HBase的体系架构图如下图所示:
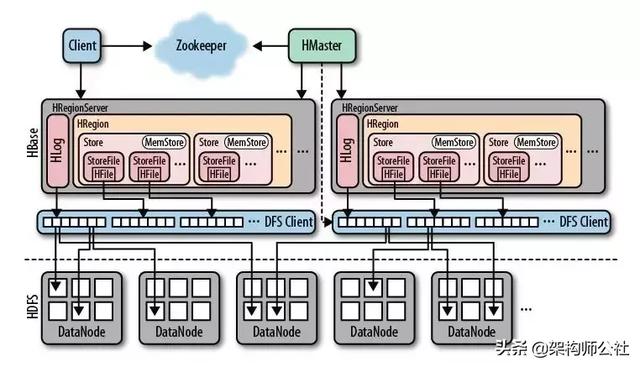
Master HBase的管理节点,在一个集群中Master一般是主备的,主备的选择是由Zookeeper实现的。
HBase Master主要职责:
- 为RegionServer分配Region;
- 负责RegionServer的负载均衡;
- 发现失效的RegionServer并重新分配其上的Region;
- 处理Schema更新请求(表的创建、删除、修改、列族的增加等)。
RegionServer
RegionServer主要负责服务和管理Region。在分布式集群中,建议RegionServer和DataNode按照1:1比例部署,这样RegionServer中的数据文件可以存储一个副本于本机的DataNode节点中,从而在读取数据时可以利用HDFS的"短路径读取(Short Circuit)"来绕过网络请求,降低读延时。
RegionServer内部管理一个或多个Region。Region许多Store组成。每个Store对用Table中的一个列族存储,即一个Store管理一个Region上的一个列族。每个Store包含一个MemStore和0到多个StoreFile。
RegionServer的主要职责:
- RegionServe维护Master分配给它的Region,处理Client对这些Region的IO请求;
- RegionServer还负责Region的Split、Compaction。
Zookeeper
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
- 为HBase提供Failover机制,选举master,避免master单点故障问题;
- 存储所有Region的寻址入口,保存hbase:meta表信息;
- 实时监控RegionServer的状态,将RegionServer的上线和下线信息实时通知给master;
- 存储HBase的Schema,包括有哪些Table,每个Table有哪些Column Family。
HDFS
HDFS为HBase提供最终的底层数据存储服务,同时为HBase提供高可用(HLog)的支持。HBase底层存储并非必须是HDFS文件系统,但是HDFS是最佳选择,也是目前应用最广泛的选择。HDFS具体功能如下:
- 提供元数据和表数据的底层分布式存储服务;
- 数据多副本,保证了高可靠和高可用性
Client
Client使用HBase的RPC机制与HMaster、RegionServer进行通信,Client与Master进行管理类通信,与RegionServer进行数据操作类通信。Client包含了访问HBase的接口,另外Client还维护了对应的cache来加速HBase的访问,比如.META.元数据信息。
RegionServer内部结构
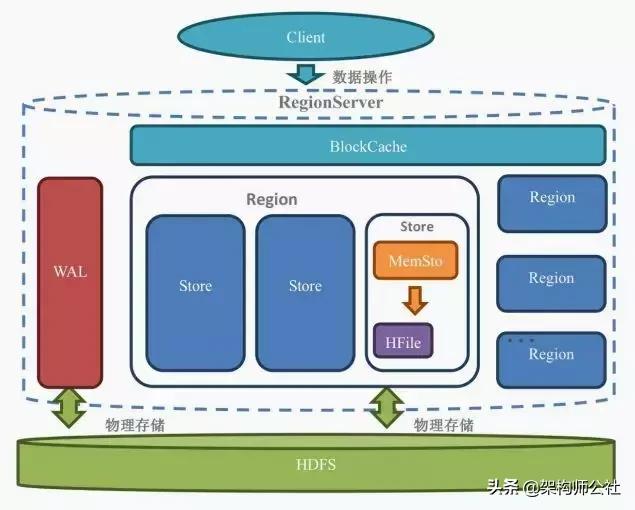
- WAL:预写日志(Write Ahead Log)。当操作到达Region的时候,HBase先把数据写到WAL中,再把数据写到MemStore中,等数据达到阈值时才会被刷写(flush)到最终存储的HFile中。WAL是一个保险机制,这样在Region的机器宕机时,由于WAL的数据是存储在HDFS中的,可以从WAL中恢复数据,所以数据并不会丢失。
- BlockCache:读缓存,用于在内存中缓存经常被读的数据。Least Recently Used (LRU) 数据在存满时会被失效。
- Region:Region相当于一个数据的分片。每一个Region都有起始rowkey和结束rowkey,这表示了Region的存储的row的范围。一个RegionServer包含多个Region,一个表的一段键值在一个RegionServer上会产生一个Region。在一个RegionServer中有一个或多个Region。
- Store:一个Region包含多个Store,一个列族分为一个Store,如果一个表只有一个列族,那么这个表在这台机器上的每一个Region里面都只有一个Store。Store是HBase的存储核心,一个Store里面有一个MemStore和一个或多个HFile。
- MemStore:有序的内存缓冲区,用于缓存还未被持久化到磁盘的数据,在持久化之前会先将数据排序,每个Region的每个列族(Store)都有一个 MemStore。
- HFile:真正存在硬盘上的,对数据按照Rowkey排好序的键值对文件。每次MemStore的flush会产生新的HFile文件。
用户写入的数据先写入WAL,然后写入MemStore,当MemStore满了以后会Flush成一个StoreFile(存储为HFile),当StoreFile数量到达一定阈值,会触发Compact合并,将多个StoreFile合并成一个StoreFile。StoreFiles合并后会逐渐形成越来越大的StoreFile,当Region内的所有的StoreFiles的总的大小超过阈值(hbase.hregion.max.filesize)会触发Split操作。会把当前Region Split成两个Region,父Region下线,新Split的两个子Region被Master分配到合适的RegionServer上,使得原先一个Region的压力分流到两个Region上。
Region寻址方式
在进行数据操作的时候,首先要定位需要对哪个Region进行操作,或者从哪个Region上读取数据,因此HBase数据读取的第一步是Region寻址。
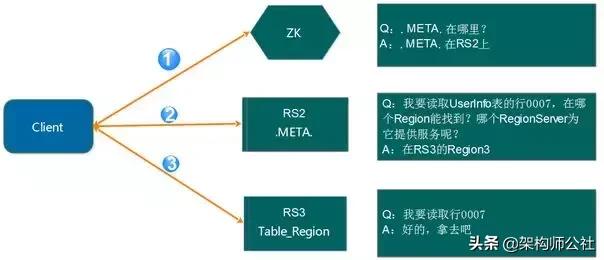
Region寻址步骤:
- 首先Client请求Zookeeper,获取hbase:meta表所在的RegionServer的地址(/hbase/meta-region-server)。
- Client连接hbase:meta表所在的RegionServer,获取需要访问的数据所在的RegionServer地址。Client会将hbase:meta表的相关信息缓存起来,以便下一次能够快速访问。hbase:meta表存储了所有Region的行键范围信息,通过这个表可以查询出你要操作的Rowkey属于哪个Region的范围里面,以及这个Region是属于哪个RegionServer。
- Client请求数据所在的RegionServer,获取所需要的数据
HBase读写流程
HBase写流程

- Client通过Region寻址定位到需要访问的RegionServer;
- 将更新写入WAL HLog,然后将更新写入MemStore,两者写入完成即返回ACK到Client;
- 判断MemStore的大小是否达到阈值,是否需要flush为StoreFile。
细节:
HBase使用MemStore和StoreFile存储对象表的更新,数据在更新的时候首先写入HLog和MemStore。MemStore中的数据时排序的,当MemStore累积到一定阈值时,就会创建一个新的MemStore并将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。同时,系统会在Zookeeper中记录一个checkpoint,表示这个时刻之前的更新已经持久化了,当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复chckpoint之后的数据。
HBase读流程
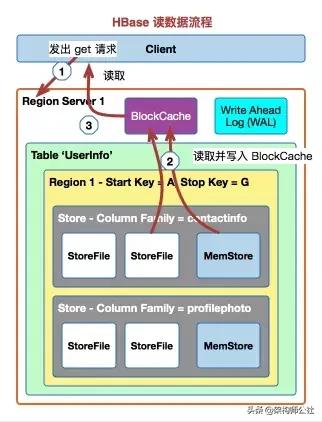
- Client通过Region寻址定位到需要访问的RegionServer
- 先从BlockCache中查找数据,找不到再去MemStore和StoreFile中查询数据
在对HBase进行写操作的时候,进行Put和Update操作的时候,其实是新增了一条数据,即使是在进行Delete操作的时候,也是新增一条数据,只是这条数据没有value,类型为DELETE,这条数据叫做墓碑标记(Tobstone)。数据的真正删除是在compact操作时进行的。
WAL机制
WAL(Write-Ahead Log,预写日志)主要用来来解决宕机之后的操作恢复问题的。数据到达Region的时候会先写入WAL,然后再被写入MemStore。就算Region的机器宕掉了,由于WAL的数据时存储在HDFS中的,所以数据并不会丢失,还可以从WAL中恢复。
HLog的生命周期
产生
所有涉及到数据的变更都会先写到HLog中,除非是关闭了HLog。
滚动
HLog的大小可以通过参数hbase.regionserver.logroll.period来控制,默认是1小时,时间达到该参数设置的时间,HBase会创建一个新的HLog文件。这就实现了HLog滚动的目的。HBase通过hbase.regionserver.maxlogs参数控制HLog的个数。滚动的目的是为了避免单个HLog文件过大的情况,方便后续的过期和删除。
过期
HLog的过期依赖于sequenceid的判断。HBase会将HLog的sequenceid和HFile最大的sequenceid(刷新到的最新位置)进行比较,如果该HLog文件中的sequenceid比刷新的最新位置的sequenceid都要小,那么这个HLog就过期了,对应HLog会被移动到/hbase/oldWALs目录。
因为HBase有主从同步的功能,这个是依赖于HLog来同步HBase的变更,所以HLog虽然过期,也不会立即删除,而是移动到别的目录中。再增加对应的检查和保留时间机制。
删除
如果HBase开启了replication,当replication执行完一个HLog的时候,会删除Zookeeper上的对应HLog节点,在HLog被移动到/hbase/oldWALs目录后,HBase每隔hbase.master.cleaner.interval(默认60秒)时间会去检查/hbase/oldWALs目录下的所有HLog,确认对应的Zookeeper的HLog节点是否被删除,如果Zookeeper上不存在对应的HLog节点,那么久直接删除对应的HLog。
hbase.master.logcleaner.ttl(默认10分钟)这个参数用来控制HLog在/hbase/oldWALs目录保留的最长时间。
MemStore刷盘
为了提高HBase的写入性能,当写请求写入MemStore后,不会立即刷盘,而是会等到一定的时候再进行刷盘操作。
发生MemStore刷盘场景:
1. 全局内存控制
当整个RegionServer中所有MemStore占用的内存达到阈值的时候,会触发刷盘的操作。
2. MemStore达到上限
当MemStore占用内存的大小达到hbase.hregion.memstore.flush.size的值的时候会触发刷盘,默认128M。
3. RegionServer的HLog数量达到上限
如果HLog太多的话,会导致故障恢复的时间过长,因此HBase会对HLog的最大个数做限制。当达到HLog的最大个数的时候,会强制刷盘(hbase.regionserver.max.logs,默认32个)。
4. MemStore达到刷写时间间隔
当MemStore达到时间间隔的阈值,会触发刷写操作,hbase.regionserver.optionalcacheflushinterval,默认3600000,即1小时,如果设置为0,则意味着关闭定时自动刷写。
5. 手工触发
可以通过hbase shell或者java api手工触发flush的操作
6. 关闭RegionServer触发
当正常关闭RegionServer会触发刷盘的操作,全部数据刷盘后就不需要再使用HLog恢复数据
7. Region使用HLog恢复完数据后触发
当RegionServer出现故障的时候,其上面的Region会迁移到其他正常的RegionServer上,在恢复完Region的数据后,会触发刷盘,当刷盘完成后才会提供给业务访问。
Region拆分
随着业务的发展,在表中的数据会越来越多,Region会越来越大,这样会严重影响数据读取效率。所以当一个Region变的过大后,会触发Split操作,将一个Region分裂成两个子Region。Region的拆分分为自动拆分和手动拆分两种。
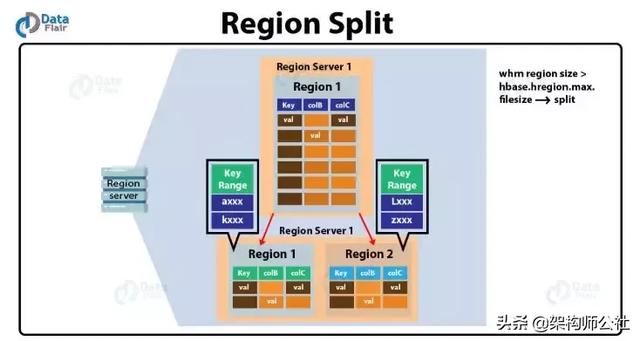
Region拆分流程
- RegionServer自身决定region拆分,并准备发起拆分。作为第一步,它将在zookeeper的分区/hbase/region-in-transition/region-name下中创建一个znode。
- 因为Master是父region-in-transition的znode节点的观察者,所以它知晓这个znode的建立。
- RegionServer在HDFS的父region目录下创建一个名为“.splits”的子目录。
- RegionServer关闭父region,强制cache刷盘并在本地数据结构中将这个region标记为offline。此时,父region的client请求将抛出NotServingRegionException,client将重试。
- RegionServer为子region A和B分别在.splits目录下的region目录,并创建必要的数据结构。然后拆分存储文件,即先在父region中创建每个存储文件两个reference文件。这两个reference文件将指向父region文件。
- RegionServer在HDFS中创建实际的region目录,并为每个子region更新相应的reference文件。
- RegionServer发起Put请求到.META.表,并在.META.表中将父region设置为offline,表并添加有关子region的信息。此时,.META.表中不会有每个子region的单独的条目。client可以通过scan .META.表来知晓父region正在拆分,但是除非子region信息记录到.META.表,否则client是看不到子region的。如果前面的Put操作成功写入到.META.表,则标志父region拆分完成。如果RegionServer在put操作前返回失败,则Master和打开这个region的RegionServer将会清除region拆分的错误状态,如果.META.表成功更新,则region拆分状态会被Master向前翻。
- RegionServer打开子region并行地接受写入请求。
- RegionServer将子region A和B,以及它们的承载者信息分别添加到.META.表。之后,client就可以发现新的region,并访问之。client本地缓存.META.表信息,但是当它们访问RegionServer或者.META.表时,本地缓存失效,client从.META.表获取新的region信息。
- RegionServer更新zookeeper的/hbase/region-in-transition/region-name节点中的region状态到SPLIT,以便master感知其状态变化。如果需要的话,负载器可以将子region自由地指定到其它region。
- region拆分完成后,其元数据和HDFS仍将包含对父region的引用。这些引用将在子region压缩重写数据文件时被删除。Master的GC任务会定期检查子region是否仍然引用父文件,如果没有,父region将被删除。
为了减少对业务的影响,Region Split过程并不会真正将父Region中的HFile数据搬到子Region目录中。Split过程仅仅是在子Region中创建了到父Region的HFile的引用文件,子Region1中的引用文件指向原HFile的上部,而子Region2的引用文件指向原HFile2的下部。数据的真正搬迁工作是在Compaction过程中完成的。
Region合并
Region的合并分为小合并(Minor Compaction)和大合并(Major Compaction)。

小合并(Minor Compaction)
当MemStore达到hbase.hregion.memstore.flush.size大小的时候会将数据刷写到磁盘,生成StoreFile。随着业务的发展,数据量会越来越大,会产生很多的小文件,对于HBase的数据读取,如果要扫描大量的小文件,会导致性能很差,因此需要将这些小文件合并成一个大一点的文件。
所谓的小合并,就是把多个小的StoreFile组合在一起,形成一个较大的StoreFile,通常是累积到3个SotreFile后执行。通过hbase.hstore.compationThreadhold参数配置,小合并的步骤如下:
- 分别读取出待合并的StoreFile文件的KeyValues,并顺序地写入到位于/hbase/.tmp目录下的临时文件中;
- 将临时文件移动到对应的Region目录中;
- 将合并的输入文件路径和输出路径封装成KeyValues写入WAL日志,并打上compaction标记,最后强制执行sync;
- 将对应region数据目录下的合并的输入文件全部删除,合并完成。
这种小合并一般速度比较快,对业务的影响也比较小。本质上,小合并就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。在Minor Compaction过程中,达到TTL(记录保留时间)的数据会被移除,但是由墓碑标记的记录不会被移除,因为墓碑标记可能存储在不同HFile中,合并可能会跨过部分墓碑标记。
大合并(Major Compation)
大合并就是将一个Region下的所有StoreFile合并成一个大的StoreFile文件。在大合并的过程中,之前删除的行和过期的版本都会被删除。大合并一般一周做一次,由hbase.hregion.majorcompaction参数控制。大合并的影响一般比较大,尽量避免同一时间多个Region进行合并,因此HBase通过hbase.hregion.majorcompaction.jitter参数来进行控制,用于防止多个Region同时进行大合并。
具体算法:
- hbase.hregion.majorcompaction参数的值乘以一个随机分数,这个随机分数不能超过hbase.hregion.majorcompation.jitter的值(默认为0.5)。
- 通过hbase.hregion.majorcompaction参数的值加上或减去hbase.hregion.majorcompaction参数的值乘以一个随机分数的值就确定下一次大合并的时间区间。
- 可以通过hbase.hregion.majorcompaction设置为0来禁用major compaction。
RegionServer故障恢复
在Zookeeper中保存着RegionServer的相关信息,在RegionServer启动的时候,会在Zookeeper中创建对应的临时节点。RegionServer通过Socket和Zookeeper建立session会话,RegionServer会周期性的向Zookeeper发送ping消息包,以此说明自己还处于存活状态。而Zookeeper收到ping包后,则会更新对应Session的超时时间。
当Zookeeper超过session超时时间还未收到RegionServer的ping包,则Zookeeper会认为该RegionServer出现故障,Zookeeper会将该RegionServer对应的临时节点删除出,并通知Master,Master收到RegionServer挂掉的信息后就会启动数据恢复流程。
更多信息来自:东方联盟网 vm888.com
- 11-06Hadoop是目前大数据领域最主流的一套技术体系
- 11-06大数据和人工智能:三个真实世界的用例
- 11-06为什么说,大数据与行业专家是“共生”关系?
- 11-06Python数据可视化:箱线图多种库画法
- 11-06这种思路讲解HDFS你肯定没见过?快速入门Hadoop必备
- 11-06媲美Pandas的数据分析工具包Datatable

- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 11-18LG新能源宣布与Bear Robotics达成合作,成为
- 11-18机构:三季度全球个人智能音频设备市场强势
- 11-18闲鱼:注册用户过6亿 AI技术已应用于闲置交
- 11-18美柚、宝宝树回应“涉黄短信骚扰”:未发现
- 11-01京东七鲜与前置仓完成融合

















 粤公网安备 44060402001498号
粤公网安备 44060402001498号