腾讯优图提出半监督对抗单目深度估计
【环球网科技综合报道】8月6日消息,记者从腾讯方面获悉,腾讯优图实验室团队在单目深度估计上取得了新的研究进展。
腾讯优图与厦门大学联合团队,共同提出了半监督对抗单目深度估计,有望充分利用海量的无标签数据所蕴含的信息,结合少量有标签数据以半监督的形式对网络进行训练。据悉,该研究成果已被人工智能领域最顶级的国际期刊TPAMI收录。
长期以来,基于深度卷积神经网络的分类、回归任务大多依赖大量的有标签数据来对网络进行训练。而在实际的算法部署中,往往只有海量的无标签数据以及非常少量的标签数据。如何充分利用这些少量的标签数据,使其达到和大量有标签数据下训练的模型相近的效果,对学术界和工业界来说一直都是一个难题。
据腾讯优图的研究员介绍,该项研究的核心难点在于,如何从无标签数据中获取监督信息。传统方法一般需要同一场景的图像序列作为输入,通过构建立体几何关系来隐式地对深度进行重建。这种方法要求同一场景至少包含两张以上的图像,一般需要双目摄像头或视频序列才可以满足。腾讯优图与厦门大学联合团队,提出在一个对抗训练的框架中,解除图像对判别器对真假样本必须为同一图像的要求,“真样本对”采用有标签数据的RGB图像以及对应的真实深度图,“伪样本对”采用无标签RGB图像以及用生成器网络预测出的深度图,由判别器网络区分预测出的深度图与对应RGB直接是否符合真实的联合概率分布,进而从无标签数据中收获监督信息。与此同时,通过添加深度图判别器,来约束预测的深度图与真实深度图的分布一致性。该方法输入可以为任意无关联图像,应用场景更加广泛。而从实验结果也发现,当主流的深度估计网络作为一个生成器网络安插在半监督框架中时,都可以收获显著的效果提升。

(图1:腾讯优图与厦门大学联合团队提出的半监督对抗框架。图中的生成器网络接收两个判别器网络的反馈来更新自己的网络参数。)
在研究的量化指标上,利用半监督对抗框架,当有标签数据很少(500张)的情况下,仅使用250张无标签RGB图像就可以收获优于其他state-of-the-art方法的效果。当固定有标签数据量(500张),持续增加无标签RGB图像可以进一步对效果带来提升,最终当利用五万张无标签RGB图像后,该方法在各项指标上都远超当前的state-of-the-art方法。

(表1:当有标签数据很少(500张)的情况下,仅使用250张无标签RGB图像就可以收获优于其他SOTA方法的效果。)

(图2:当固定有标签数据量(500张),持续增加无标签RGB图像可以进一步对效果带来提升)

(图3. 仅使用500张有标签数据训练的模型效果。从左到右依次为RGB图像、真实深度图和优图算法预测的深度图。通过利用额外的无标签RGB数据,优图算法仅使用少量数据就可以达到较好的视觉效果)
据腾讯优图的研究员介绍,该研究方法虽然以单目深度预测为实验,但过程中发现对于语义分割任务也有相似的效果提升。与此同时,当模型训练与算法部署的环境存在差异时(即存在Domain Shift),若有标签数据为源域中的数据,而无标签数据为算法部署的目标域中的数据,该方法还可以起到Domain Adaptation的效果,提升模型在目标域的部署效果,该观察也在非同源场景下的ReID任务中得到了初步的验证。
总的来说,该项研究的核心在于充分挖掘无标签样本所蕴含的信息,减少对标签数据的依赖,未来有望在场景重建、非同源场景ReID等多个方案中进行应用。


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 11-18LG新能源宣布与Bear Robotics达成合作,成为
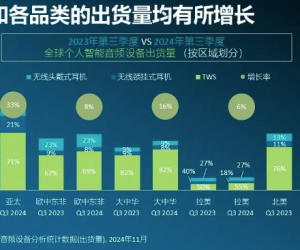
- 11-18机构:三季度全球个人智能音频设备市场强势
- 11-18闲鱼:注册用户过6亿 AI技术已应用于闲置交
- 11-18美柚、宝宝树回应“涉黄短信骚扰”:未发现
- 11-01京东七鲜与前置仓完成融合












 粤公网安备 44060402001498号
粤公网安备 44060402001498号