mysql大表更新sql的优化策略
问题sql背景:项目有6个表的要根据pid字段要写入对应的brand_id字段。但是这个其中有两个表是千万级别的。我的worker运行之后,线上的mysql主从同步立刻延迟了!运行了一个多小时之后,居然延迟到了40分钟,而且只更新了十几万行数据。问题sql如下:
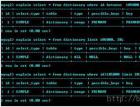
<!-- 根据商品id更新品牌id --> <update id="updateBrandIdByPid" parameterClass="com.jd.chat.worker.domain.param.UpdateBrandIdParam"> UPDATE $tableName$ SET brand_id = #newBrandId# WHERE pid = #pid# AND brand_id = 0 </update>项目组的mysql专家帮我分析了下,因为pid字段没有索引,mysql引擎要逐行扫描出与传入的pid值相等的列,然后更新数据,也就是要扫描完1000W+行磁盘数据才能执行完这个sql。更严重的是,这个千万级的表里面有多少个不同的pid,我就要执行多少个这样的sql。
同事给我的建议的根据id字段进行sql代码层次的纵向分表。每次更新1000行的数据,这样mysql引擎就不用每次在扫全表了,数据库压力是之前的万分之一。而且id作为主键,是有索引的有索引,有索引能大大优化查询性能,优化后的sql如下:
<!-- 根据商品id更新品牌id --> <update id="updateBrandIdByPid" parameterClass="com.jd.chat.worker.domain.param.UpdateBrandIdParam"> UPDATE $tableName$ SET brand_id = #newBrandId# WHERE pid = #pid# AND brand_id = 0 AND id BETWEEN #startNum# AND #endNum# </update>仅仅用了id限区间的语句,将一个千万级的大表代码层次上进行纵向切割。重新上线worker后,mysql主从没有任何延迟!而且经过监视,短短10分钟就更新了十几万数据,效率是之前的6倍!更重要的是数据库负载均衡,应用健康运行。
>更多相关文章
- 10-26高手浅谈MySQL数据库的几个安全问题
- 10-26MySQL False 黑客注入及技巧总结
- 02-2514种最好方法保护MySQL全面安全
- 12-23mysqltoolkit用法[备忘]
- 12-23一个基于MySQL的Key-List存储方案
- 12-21ODBC中遇到的错误
- 12-21使用mysql遇到的问题
- 12-21PAIP.MYSQLSLEEP连接太多解决
首页推荐

佛山市东联科技有限公司一直秉承“一切以用户价值为依归
- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-01“AI复活”生意的启示与挑战
- 04-01超200万人涌入直播间看卖“云” 上千家企业
- 04-01从虚拟到共生:数字人“花样百出”
- 03-29小米汽车“走进”京东,双方或将深化合作
- 03-29迎广交会,广州白云国际机场优化支付服务示
相关文章
![mysqltoolkit用法[备忘]](/d/file/database/MYSQL/2013-12-23/04bc6d6d44f8997289d0a8a3716d5896.png)
24小时热门资讯
24小时回复排行
热门推荐
最新资讯




操作系统
黑客防御




 粤公网安备 44060402001498号
粤公网安备 44060402001498号