数据库综合系列之视图
视图可以看作定义在SQL Server上的虚拟表.常规视图本身并不存储实际的数据,而仅仅存储一个Select语句和所涉及表的metadata.
对数据操作建立在之前建立的表基础上:
具体见http://blog.csdn.net/buyingfei8888/article/details/17399837
为什么要使用视图(View)
从而我们不难发现,使用视图将会得到如下好处:
视图隐藏了底层的表结构,简化了数据访问操作
因为隐藏了底层的表结构,所以大大加强了安全性,用户只能看到视图提供的数据
使用视图,方便了权限管理,让用户对视图有权限而不是对底层表有权限进一步加强了安全性
视图提供了一个用户访问的接口,当底层表改变后,改变视图的语句来进行适应,使已经建立在这个视图上客户端程序不受影响
视图(View)的分类
视图在SQL中可以分为三类
1. 普通视图(Regular View)
2. 索引视图(Indexed View)
3. 分割视图(Partitioned View)
视图(View)的最佳实践
一定要将View中的Select语句性能调到最优(貌似是废话,不过真理都是废话…)
View最好不要嵌套,如果非要嵌套,最多只嵌套一层
能用存储过程和自定义函数替代View的,尽量不要使用View,存储过程会缓存执行计划,性能更优,限制更少在分割视图上,不要使用聚合函数,尤其是聚合函数还包含了Distinct在视图内,如果Where子句能加在视图内,不要加在视图外(因为调用视图会返回所有行,然后再筛选,性能杀手,如果你还加上了order by…..)
下面对三种视图的应用,主要是普通视图
1 普通视图
创建视图:
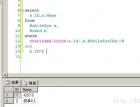
[sql] view plaincopyprint?01.create view shopSale
02.as
03.select s_name 商店名字,s_address 商店地址,c_name 销售人员 from t_shop,t_cash_housewoker where s_id in(select s_id from manage where m_id=1) and t_cash_housewoker.m_id=1
create view shopSale
as
select s_name 商店名字,s_address 商店地址,c_name 销售人员 from t_shop,t_cash_housewoker where s_id in(select s_id from manage where m_id=1) and t_cash_housewoker.m_id=1
使用:
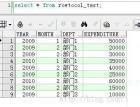
[sql] view plaincopyprint?01.select * from shopSale
select * from shopSale2 索引视图
其实索引视图也很类似,在普通的视图的基础上,为视图建立唯一聚集索引,这时这个视图就变成了索引视图.
索引视图可以看作是一个和表(Table)等效的对象!
聚集索引简单来说理解成主键,数据库中中的数据按照主键的顺序物理存储在表中,就像新华字典,默认是按照ABCD….这样的方式进行内容设置。ABCD….就相当于主键.这样就避免了整表扫描从而提高了性能.因此一个表中只能有一个聚集索引。
为一个视图加上了聚集索引后。索引视图会将数据物理存在数据库中,索引视图所存的数据和索引视图中所涉及的底层表保持同步。
理解了索引视图的原理之后,我们可以看出,索引视图对于OLAP这种大量数据分析和查询来说,性能将会得到大幅提升。尤其是索引视图中有聚合函数,涉及大量高成本的JOIN,因为聚合函数计算的结果物理存入索引视图,所以当面对大量数据使用到了索引视图之后,并不必要每次都进行聚合运算,这无疑会大大提升性能.
而同时,每次索引视图所涉及的表进行Update,Insert,Delete操作之后,SQL Server都需要标识出改变的行,让索引视图进行数据同步.所以OLTP这类增删改很多的业务,数据库需要做大量的同步操作,这会降低性能。
谈完了索引视图的基本原理和好处与坏处之后,来看看在SQL Server中的实现:
在SQL Server中实现索引视图是一件非常,简单的事,只需要在现有的视图上加上唯一聚集索引
但SQL Server对于索引视图的限制却使很多DBA对其并不青睐:
比如:
索引视图涉及的基本表必须ANSI_NULLS设置为ON
索引视图必须设置ANSI_NULLS和QUOTED_INDETIFIER为ON
索引视图只能引用基本表
SCHEMABINDING必须设置
定义索引视图时必须使用Schema.ViewName这样的全名
索引视图中不能有子查询
avg,max,min,stdev,stdevp,var,varp这些聚合函数不能用
3 分割视图总体上可以分为两种:
1.本地分割视图(Local Partitioned View)
2.分布式分割视图(Distributed Partitioned View)
因为本地分割视图仅仅是为了和SQL Server 2005之前的版本的一种向后兼容,所以这里仅仅对分布式分割视图进行说明.
分布式分割视图其实是将由几个由不同数据源或是相同数据源获得的平行数据集进行连接所获得的
上面的视图所获得的数据分别来自三个不同数据源的表,每一个表中只包含四行数据,最终组成了这个分割视图.
使用分布式分割视图最大的好处就是提升性能.比如上面的例子中,我仅仅想取得ContactID为8这位员工的信息,如果通过分布式视图获取的话,SQL Server可以非常智能的仅仅扫描包含ContactID为8的表2,从而避免了整表扫描。这大大减少了IO操作,从而提升了性能.
这里要注意的是,分布式分割视图所涉及的表之间的主键不能重复,比如上面的表A ContactID是1-4,则表B的ContactID不能是2-8这个样子.
还有一点要注意的是,一定要为分布式分割索引的主键加Check约束
通过视图(View)更新数据
通过视图更新数据是我所不推荐的.因为视图并不能接受参数.我更推荐使用存储过程来实现.
使用View更新数据和更新Table中数据的方式完全一样(前面说过,View可以看作是一个虚拟表,如果是索引视图则是具体的一张表)
通过视图来更新数据需要注意以下几点
1.视图中From子句之后至少有一个用户表
2.View的查询无论涉及多少张表,一次只能更新其中一个表的数据
3.对于表达式计算出来的列,常量列,聚合函数算出来的列无法更新
4.Group By,Having,Distinct关键字不能影响到的列不能更新
具体代码:
[sql] view plaincopyprint?01.update shopSale set 销售人员='销售人员一' where 销售人员='销售1'
update shopSale set 销售人员='销售人员一' where 销售人员='销售1'
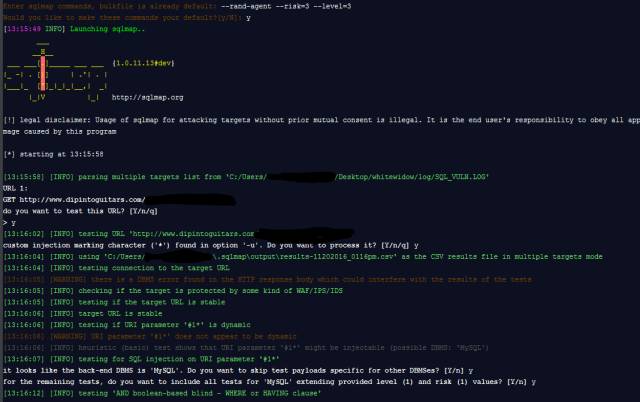
- 10-26Whitewidow SQL漏洞扫描工具演示
- 10-26SQL黑客注入防御与绕过的多种姿势
- 12-23SQLServer数据库操作总结(sql语法的使用)
- 12-21C#连接Sqlite
- 12-21ORACLE数据库学习之SQL性能优化详解
- 12-21解决SQLSERVER2008数据库日志文件占用硬盘空间问题
- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-01“AI复活”生意的启示与挑战
- 04-01超200万人涌入直播间看卖“云” 上千家企业
- 04-01从虚拟到共生:数字人“花样百出”
- 03-29小米汽车“走进”京东,双方或将深化合作
- 03-29迎广交会,广州白云国际机场优化支付服务示
![[SQLServer]发送HTML格式邮件](/d/file/database/SQLServer/2013-12-21/e4cf8ee11e5808af02776facb796ca42.jpg)









 粤公网安备 44060402001498号
粤公网安备 44060402001498号